By: DJ Spatoulas
Published: 29 Mar 2022
Last Updated: 19 May 2025
When designing new systems, one of the key considerations of each system is how the data will be stored and queried. While most of our major products and services still primarily store data in a traditional relational database management system (RDBMS), our migration from a traditional monolithic web application to a microservice-based architecture has enabled our Engineering teams to use purpose-built databases as an alternative data storage solution for critical functions of the KnowBe4 platform.
While it is not applicable to all projects, there are significant advantages of using DynamoDB in certain workflows or to solve certain types of use cases. However, the choice of DynamoDB as a data store comes with technical and personnel based trade-offs, and it can quickly become difficult for engineering teams to build additional features into a system using DynamoDB if the data access patterns of the system are likely to change over time. Data modeling in a NoSQL database is different from in a traditional RDBMS, and requires a significantly larger amount of time spent in the table design phase than normalizing data across a series of relational tables.
The best way to learn DynamoDB is to start using it in a non-critical system. Like any new technology, the easiest way to try it is in a use case for an internal project, preferably one that is well encapsulated and relatively small in scope. It is important to discuss the success criteria for the project before the technology is introduced, so that stakeholders can prepare for the impact of the new technology in the stack. When considering a new programming language, technology, or 3rd party service, it is important for engineering leaders to understand and willingly accept its advantages and disadvantages from the perspective of an engineering organization, rather than solely on its impact on a specific project. If your organization leverages AWS as its cloud provider, using DynamoDB can be a cost-efficient and highly-scalable data storage solution, especially when compared to traditional RDBMS solutions.
From an engineer's perspective, it's intuitive to start working with data in a DynamoDB table following the official DynamoDB Developer's Guide. Engineers can leverage DynamoDB Local for local development against a DynamoDB compatible interface, which is critical to iterating quickly without having to provision resources in AWS. Most of the KnowBe4 Platform Engineering services are AWS Lambda Functions, and leverage one of the official AWS Lambda Container Images as a base image.
version: "3.8"
volumes:
dynamodb_data: {}
services:
lambda:
build:
context: .
volumes:
- './src:/var/app/src'
ports:
- "9000:8080"
links:
- dynamodb
ulimits: # This is the limit set in AWS Lambda
nofile:
soft: 1024
hard: 1024
environment:
SERVICE: counter
DDB_TABLE_NAME: counter-db
DDB_ENDPOINT_URL: http://dynamodb:8000
AWS_REGION: us-test-1 # Intentionally set this to an invalid region
dynamodb:
image: amazon/dynamodb-local
command: -jar DynamoDBLocal.jar -sharedDb -dbPath /home/dynamodblocal
volumes:
- dynamodb_data:/home/dynamodblocal
ports:
- "8000:8000"
The stack is optimized to produce fast feedback loops for the developer, and is an accurate emulation of how the service will run in the production AWS account. Using the sample docker-compose.yml, the entire stack can be started using docker-compose up.
❯ docker-compose up
Starting example_dynamodb_1 ... done
Recreating example_lambda_1 ... done
Attaching to example_dynamodb_1, example_lambda_1
dynamodb_1 | Initializing DynamoDB Local with the following configuration:
dynamodb_1 | Port: 8000
dynamodb_1 | InMemory: false
dynamodb_1 | DbPath: /home/dynamodblocal
dynamodb_1 | SharedDb: true
dynamodb_1 | shouldDelayTransientStatuses: false
dynamodb_1 | CorsParams: *
dynamodb_1 |
lambda_1 | time="2021-11-11T20:19:20.035" level=info msg="exec '/var/runtime/bootstrap' (cwd=/var/app, handler=)"Note: See the official AWS Runtime API docs for more details.
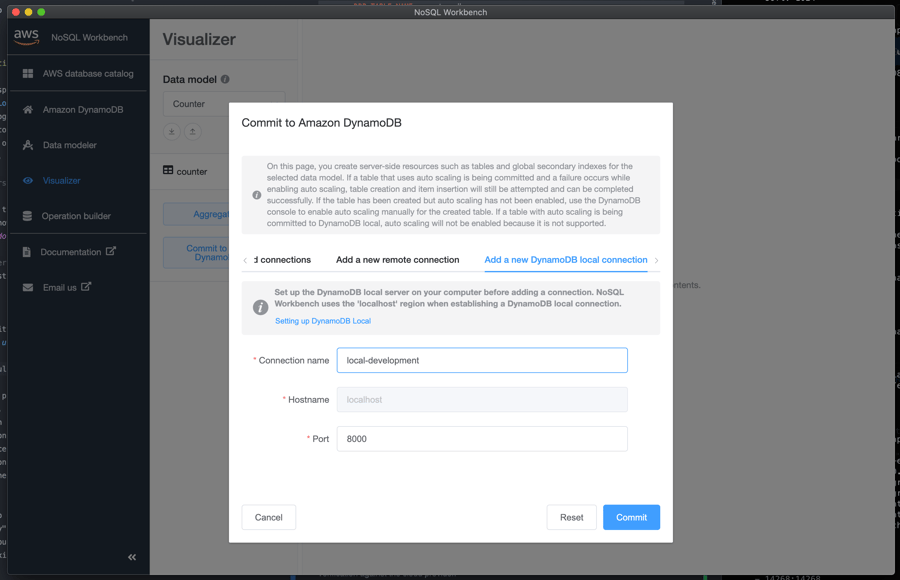
In order to interact with both local and cloud DynamoDB tables, our team leverages the NoSQL Workbench.
NoSQL Workbench is a unified visual IDE tool that provides data modeling, data visualization, and query development features to help you design, create, query, and manage DynamoDB tables.
The NoSQL Workbench is helpful for data modeling against the known set of requirements, and makes it easy to test the anticipated data access patterns before writing any code. One of the most useful features is the ability to provision tables directly through the workbench console, allowing engineers to test table modifications manually before committing the changes to the project's terraform configuration. This feature has been particularly helpful when preparing for data migrations, or in situations where an engineer's account does not have access to the required functions to perform these operations in the AWS console.
The AWS SDKs have well-supported documentation, and are available for most of the popular programming languages. Having recently completed a handful of projects in Rust, we are currently in the process of migrating from the Rusoto library to the alpha release of AWS Rust SDK.
Here is an example of writing an item to a DynamoDB table using the Rust SDK for DynamoDB.
use aws_config::default_provider::credentials::default_provider;
use aws_sdk_dynamodb::{Client, Endpoint, Region};
use envconfig::Envconfig;
use lambda_runtime::{handler_fn, Context, Error};
use serde::Serialize;
use serde_dynamo::aws_sdk_dynamodb::to_item;
use serde_json::Value;
use std::sync::Arc;
use uuid::Uuid;
#[derive(Debug, Envconfig)]
struct Config {
#[envconfig(from = "AWS_REGION", default = "us-local-1")]
pub region: String,
#[envconfig(from = "DYNAMODB_TABLE_NAME")]
pub table_name: String,
#[envconfig(from = "DYNAMODB_ENDPOINT")]
pub endpoint: Option<String>,
}
async fn create_dynamodb_client(config: Config) -> Client {
match config.endpoint {
None => {
let aws_cfg = aws_config::load_from_env().await;
Client::new(&aws_cfg)
}
Some(endpoint) => {
let dynamodb_uri = endpoint.parse().unwrap();
let dynamodb_cfg = aws_sdk_dynamodb::Config::builder()
.region(Region::new(config.region))
.endpoint_resolver(Endpoint::immutable(dynamodb_uri))
.credentials_provider(default_provider().await)
.build();
Client::from_conf(dynamodb_cfg)
}
}
}
#[derive(Debug, Serialize)]
struct Counter {
id: Uuid,
value: i64,
}
async fn lambda_handler(
dynamodb_client: Arc<Client>,
table_name: String,
_event: Value,
_context: Context,
) -> Result<(), Error> {
let value = Counter {
id: Uuid::new_v4(),
value: 0,
};
let item = to_item(value)?;
let response = dynamodb_client
.put_item()
.table_name(&table_name)
.set_item(Some(item))
.send()
.await?;
println!(
"Wrote Counter to table [{}] | Response: {:?}",
&table_name, response
);
Ok(())
}
#[tokio::main]
async fn main() -> Result<(), Error> {
let config: Config =
Config::init_from_env().expect("The config must init from the environment variables");
let table_name = String::from(&config.table_name);
let dynamodb_client: Arc<Client> = Arc::new(create_dynamodb_client(config).await);
let lambda_function = handler_fn(move |event, context| {
let dynamodb_client = Arc::clone(&dynamodb_client);
let table_name = table_name.clone();
async {
lambda_handler(dynamodb_client, table_name, event, context)
.await
.map_err(|err| {
println!("Lambda Handler returned an error: {:?}", err);
err
})
}
});
lambda_runtime::run(lambda_function).await
}The behavior and use of the AWS SDK is consistent across the various supported programming languages, and the libraries are generally intuitive since each is written idiomatically in the target language.
Here is an example of writing the same item to a DynamoDB table using Boto3, the AWS SDK for python.
import os
import boto3
import uuid
from boto3.dynamodb import types
AWS_REGION = os.environ["AWS_REGION"] # Set to "localhost" for local testing
DDB_TABLE_NAME = os.environ["DDB_TABLE_NAME"]
DDB_ENDPOINT_URL = os.getenv("DDB_ENDPOINT_URL") # Set the "dynamodb:8000" for local dynamodb service url
def from_item(item: dict) -> dict:
"""
Converts from DynamoDB JSON (with type annotations) to standard JSON
:param item:
:return:
"""
deserializer = types.TypeDeserializer()
return {k: deserializer.deserialize(v) for k, v in item.items()}
def to_item(value: dict) -> dict:
"""
Converts to DynamoDB JSON (with type annotations) from standard JSON
:param value:
:return:
"""
serializer = types.TypeSerializer()
return {k: serializer.serialize(v) for k, v in value.items()}
def create_dynamodb_client():
return boto3.client(
"dynamodb",
region_name=AWS_REGION,
endpoint_url=DDB_ENDPOINT_URL,
)
def main():
dynamodb_client = create_dynamodb_client()
value = {
"id": str(uuid.uuid4()),
"value": 0,
}
response = dynamodb_client.put_item(
TableName=DDB_TABLE_NAME,
Item=to_item(value)
)
print(f"Wrote Counter to table [{DDB_TABLE_NAME}] | Response: {response}")
if __name__ == "__main__":
main()
Syntax differences aside, the code snippet above would look very similar in any of the supported languages, since the modules in the SDKs are closely modeled after the API interface of the AWS services. The SDKs closely follow the examples and usages shown in the developer guide, and are usually up-to-date with the currently available version of the various AWS services.
Using DynamoDB requires engineers to learn and apply standard NoSQL data modeling techniques, in addition to learning the specifics of the DynamoDB service. The AWS Documentation provides some general guidance on the topic, and outlines a few key differences between NoSQL vs RDBMS.
These differences make database design different between the two systems:
- In RDBMS, you design for flexibility without worrying about implementation details or performance. Query optimization usually doesn't affect schema design, but normalization is important.
- In DynamoDB, you design your schema specifically to make the most common and important queries as fast and as inexpensive as possible. Your data structures are tailored to the specific requirements of your business use cases.
Part of designing a DynamoDB table is determining the key structure used by the application, which should be optimized for the most frequently used data access patterns. It is also the recommendation of AWS to limit the number of tables used by a single application. If you're wondering where to start, check out the post from Alex Debrie, author of the DynamoDB Book, The What, Why, and When of Single-Table Design with DynamoDB.
One of the main differences an engineer is likely to experience when working with DynamoDB is investing a lot more time understanding the access patterns of the data before deciding how it would be best stored in the datastore. The design of a system's key structure becomes increasingly difficult to change as the system matures, and it can quickly become impossible to support new or changes to existing product requirements that introduce new data access patterns without significant data migration or manipulation effort.
The key design of a DynamoDB table can also have a significant impact on the complexity of the codebase that is responsible for performing the data access layer operations. Ultimately, there are many approaches to key design in DynamoDB and many of them come with tradeoffs depending on the use case and context of the current engineering organization. One of the key benefits of the DynamoDB Streams feature is the ability to publish updates from one system to another after the item(s) have been written to the datastore. This feature can be used in a variety of ways to address common operational requirements like data migrations, upgrade scripts and even trigger additional writes to one or more DynamoDB tables.
When considering a new data storage technology, it is important to consider the level of impact the new technology will have on the development team once it has been introduced to the stack and how well it will mesh with the current set of technologies we are already using.
Many of the Platform Services at KnowBe4 leverage a stream processor to publish events to a message broker, process incoming and outgoing callbacks, and replicate data to another data store. In certain services, it would be possible to migrate from DynamoDB to another type of datastore, but the difficulty of a datastore migration is often highly dependent on the quality of the test harness for the current implementation. Without a reliable method of change validation in the CI/CD process, the cost of a migration away from DynamoDB would increase significantly.
While there isn't a need to perform schema migrations often, the update process for a key migration can be difficult to implement in production environments using DynamoDB as the primary data store. The risk of failure increases in data migrations or update scripts that target multiple partitions of the table in a way that could damage the integrity of the service's data. When selecting a partition strategy in DynamoDB, it is important to use write sharding to distribute the operations evenly and avoid designing workloads in which the required operations exceed the i/o capacity for a single partition.
DynamoDB Streams are one of the most popular DynamoDB features within KnowBe4 Engineering, and have been a featured architectural component in a number of projects recently. The ability to process INSERT, MODIFY and REMOVE events from DynamoDB tables asynchronously from the actual save operation enables our systems to react to certain events based on state changes, as well as the ability to publish transactions from an internal data store within the domain. There are multiple streaming configuration options available, including integrations to Kinesis Data Streams and AWS Lambda.
By specifying a Time to Live (TTL) key on a DynamoDB table, our engineers can design data lifecycle policies that automatically remove items from the table after the items are no longer relevant. The removal of an expired item from the table inserts a REMOVE item event into the DynamoDB Stream, and can be processed asynchronously by a stream reader. Many of the KnowBe4 Platform Engineering services leverage the TTL feature to lifecycle data from the primary data store to an archive in S3 or another long term storage solution.
Using serverless infrastructure provides the ability to scale very quickly in order to support workflows that are unpredictable, and helps reduce the overhead on the reliability engineering teams responsible for monitoring and tuning the systems here at KnowBe4. Many of our DynamoDB tables are designed in a way that leverages the partition key to create strong tenant isolation at the data layer and distribute the workloads across one or more customer partitions. Another significant advantage of using DynamoDB is the consistent performance as the size of the table increases, which is particularly beneficial when building a multi-tenant data storage solution. Finally, the DynamoDB pay-per-use model is usually a more cost-effective solution than provisioned infrastructure like an RDS Aurora or OpenSearch cluster.
When working with DynamoDB, engineers will inevitably need access to the data to troubleshoot and help debug an issue. Certain workflows, such as writing data migrations or changing the partition design, require a dataset to start in a known state and the ability to reset to that initial state as many times as needed. The granularity of IAM policies gives administrators an easy way to grant engineers access to non-production environments, and to add permissions for access to production tables, by resource, when needed.
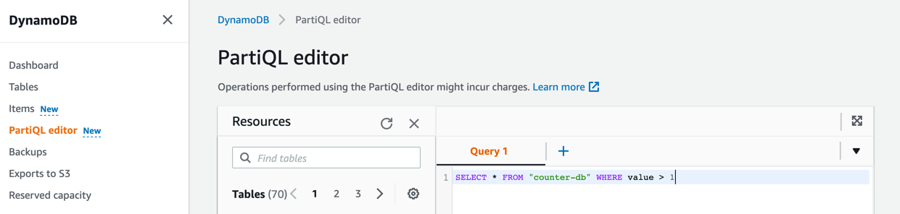
DynamoDB Administrators have the ability to query the production data directly from the AWS console using either the standard DynamoDB expression language or a subset of PartiQL, which provide a SQL-Compatible Query language for DynamoDB.
DynamoDB allows us to meet the internal requirements for disaster recovery by providing both on-demand and continuous backups with point-in-time recovery. Even better, the on-demand backup and restore process runs without degrading the performance or availability of the table, making it safe to run in production environments. Engineers can manually create and restore backups of tables across environments to help debug issues within the data layer.
The decision to use Amazon DynamoDB for production services should not be made lightly. There are many specific features and requirements that must be met and well-understood in order for the service to be successful. However, taking the time to plan and research these aspects in the context of your service can result in software that is incredibly scalable, secure, easy to test, and quick to build. Not all projects or services lend themselves well to Amazon DynamoDB, but we have often found that the tradeoffs we must make to build software in this way are well worth the extra initial effort and result in a more pleasant experience for both our engineers internally, but most importantly for our customers.
Have something to contribute? Passionate about purpose-driven, highly-productive software development? Send us an application! KnowBe4 Engineering is always looking for more talented engineers just like you! Check our open positions on our jobs page - www.knowbe4.com/careers.


KnowBe4 Engineering heavily uses On-Demand environments for quick iterations on native cloud-based…

How KnowBe4 solved the "It Works on My Machine" problem with a new approach to provisioning test…