By: KnowBe4 HR
Published: 17 Jan 2023
Last Updated: 19 Jun 2026
Conway's law is named after the computer programmer Melvin Conway, who in 1967 claimed that "Any organization that designs a system will produce a design whose structure is a copy of the organization's communication structure." In the field of software architecture, a complex product ends up shaped like the organization structure they are designed in.
Graphene is the backend system that powers KnowBe4's SecurityCoach product. Before we start explaining the microservice style in Graphene, it is useful to compare it to the monolithic style. In a monolithic style architecture, applications are built as a single unit. In a micrososervice style architecture, applications are divided into individual services that model a business domain. Such services can be deployed independently. The diagram below Fig. 1 clearly shows the difference between these two architectural styles.
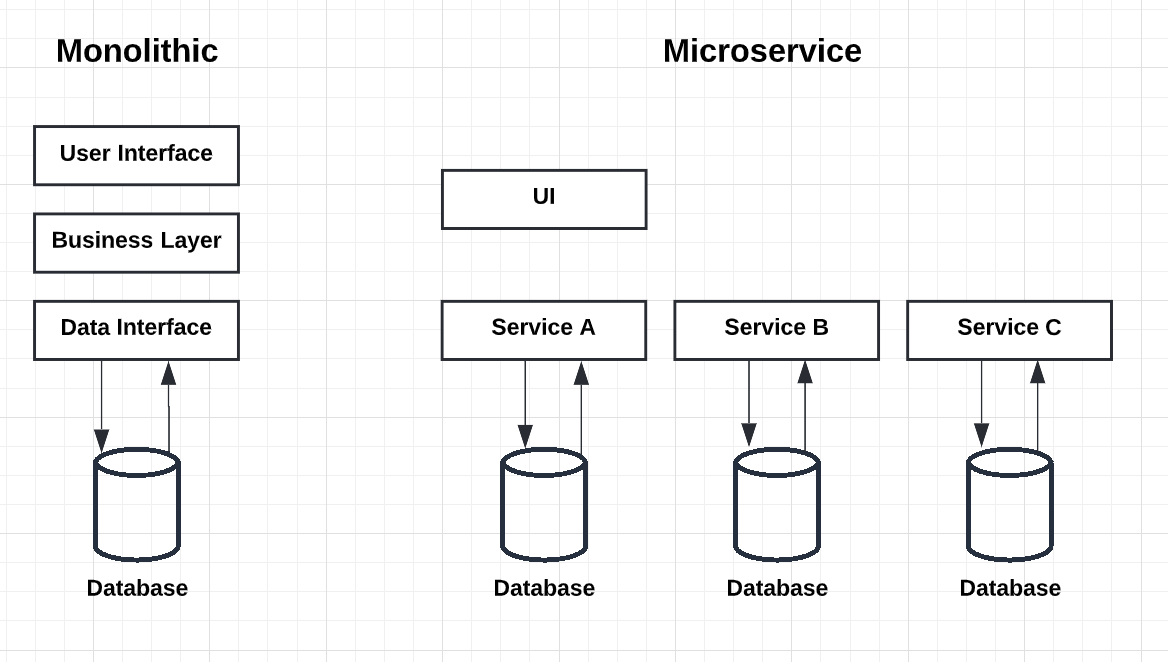 Fig. 1 Monolithic vs Microservice Architecture
Fig. 1 Monolithic vs Microservice Architecture
We would like to share with you our journey of migrating a Monolith into Microservices. From product perspective, Graphene integrates with leading cybersecurity products including Crowdstrike, Zscaler, Okta, Netskope and many others. The Graphene platform analyzes real-time user behavior that poses a potential security risk and pushes micro-learning modules to educate and inform the user in response to their risky behavior.
The Graphene Architecture has evolved over the last 3 years. In this section, we will briefly review our journey finding the right architecture for this data-intensive application.
We started our journey back in 2019. As you can guess, the first version of Graphene was a monolithic system. For a start-up, this was the right choice. We used Django and its built-in Model-View-Controller (MVC) pattern. In Django, with respect to MVC, most of the good stuff happens in the Model-Template-View (MTV). We had HTML templates and database models in one single code repository.
We had the entire team contributing to this single codebase. According to Conway's law that "software architecture reflects the structure of the team", it is not surprising that a monolithic architecture was developed. A monolithic system was much faster to build in the early days. It also enabled us to iterate faster by incorporating early customers' feedback to improve the product.
However, we started to pay for the cost with constant fire-drills when there were frequent production outages. It was uncanny when every Friday afternoon seems to stir up the kraken in the monolith!
As more and more customers started to use this security awareness product, we started to run into scalability and performance issues. We could not deliver our micro-learning modules to the end users in real-time. It was time to break the monolith. The obvious candidates were to tackle the data intensive and I/O intensive parts first. Therefore, our analytics service (and corresponding data team) and vendor integration service (vendors team) were born. Mr. Conway was proving to be right all along.
With the heavy lifting functions out of our monolith, life seemed good again. But only for very short period of time. Customers loved us so much that we grew rapidly in a few months!
In the Analytics Service, we stored all (many millions) events in a relational database. We were running tons of celery tasks to process and implement business logics, all in one single container-based service. We ran into CPU and memory limits all the time. At the data layer, relational database was not a good fit for our application. We found that SQL aggregate functions in a relational database did not perform well. We realized that some non-SQL datastore were needed, and that we had to decompose the system further to support more customers. (How micro can you go?!)
In early 2021, our migration from Monolith to Microservices gained full speed. We moved some of the celery tasks above to other services, each had their own code repository. We also started to introduce a queueing system into our event processing pipelines. AWS's S3 notification service (SNS) was used to notify the arrival of events. We ran many celery tasks in many containers to check SQS queues for new events to process. Because the architecture was not event-driven, we had to run a while loop to check the SQS queues 24/7. As you can imagine, the AWS bill was too large (Accounting team was ballistic! Thank God for working remotely!). Something had to be done to make this architecture scalable and cost effective (...and ensure our team's safety :-)).
In early 2022, KnowBe4, the world's largest integrated platform for security awareness training, started to integrate Graphene into the security awareness training platform. Our first instinct was to integrate Graphene as a black box with well-defined APIs, which is par for the course during early days of any acquisition. However, KnowBe4 backend was already drinking from the sweet fountain of event driven services pattern. During this re-architecture journey, we first looked at Graphene in a monolithic bounded context, then decomposed the bounded context further to find those sought-after event driven Microservices. We created one code repository for each service, so that each team can work independently.
If you look at Fig. 2, you notice that we use Lambda Functions in almost all services. The shift from container-based architecture to serverless architecture brought lots of benefits, one of which is the infrastructure cost saving (I started working from my desk now, accounting team called off the hunt!). Lambda functions are on-demand containers with at most 15min lifetime. We only pay for what is running. The serverless architecture also reduces DevOps cost, because everything is managed by the cloud provider. It was clear that the Event Driven Microservice Architecture is the right architecture. In the rest of this article, we will briefly describe the services we have built, the benefits we got, and the challenges we faced.
In Graphene, we have 10 different services. Each service has its own database and public endpoints. On a very high level, Graphene is comprised of services in the following categories: Event Ingestion Service, Event Enrichment Service, Threat Detection Service, real-time Messaging Service, and Utility Service.
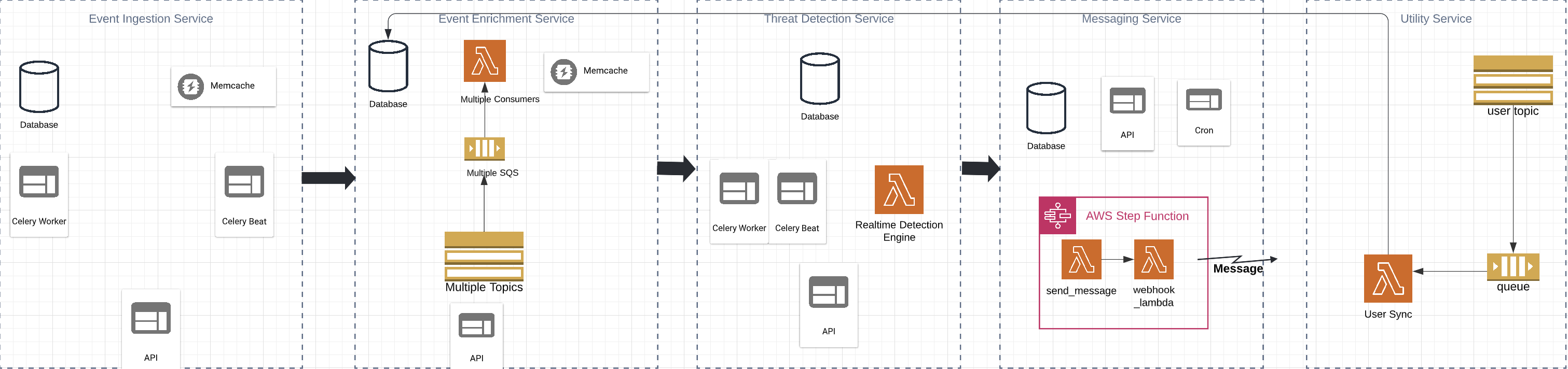 Fig. 2 Graphene Microservice Architecture
Fig. 2 Graphene Microservice Architecture
Event Ingestion Service is responsible for integration with all 3rd party security vendors. The service provides endpoints for customers to set up vendors. After vendors are set up, this service fetches events from these vendors. All raw and enriched events are stored in a S3 bucket, where other downstream services (e.g., Event Enrichment Service) listen for the S3 notification and processes the events. Such processing model is called Event‐Driven Process Chains (EPCs).
Event Enrichment Service is responsible for adding various meta data to the event to give it a richer context for downstream services. To achieve this, we have multiple engines working together to enrich and filter events. Each engine in the Event Enrichment Service is implemented as a Lambda Function. The Lambda is triggered by multiple SQS that subscribe to different topics configured for different folders in a S3 bucket (Fig. 2).
In our Event‐Driven Process Chains, the real-time Detection Engine listens for enriched events, and runs them through our patented algorithms to determine a real-time coaching moment. These moments are posted on the user's event timeline (not shown in this article), and then passed on for delivery to the messaging service.
This service is used to deliver SecurityTips or training notifications to end users at risk in real-time. The service utilizes AWS Step Function to send messages to users who use slack/teams app, then invoke a webhook to update message delivery status. See Fig. 2 for more details.
This service is designed to provide utilities for other Graphene services to use. We can implement many common utilities in this service. Currently User Sync Utility is part of the service. User Sync Utility is used to sync user data from external system to the Event Enrichment Service in Graphene.
Under the hood, this utility is implemented as a Lambda (User Sync Lambda in Fig. 2), which is triggered by SQS that subscribes to all user data change events (S3 bucket notifications or AWS SNS). These changes are then processed and stored in a RDS database in the Event Enrichment Service. Below is a sample user record stored in the database.
"org_id": 1,
"user_id": 1,
"email": "xyz@dot.com",
"tag1": "CT",
"tag2": "10111",
"tag3": "1079",
"tag4": "School",
"department": "10145 - IT",
"employee_number": "",
"first_name": "Eric",
"last_name": "Doe",
"location": "1021",
"employee_title": "Director 10145",
"manager_email": "john@marketing.com",In microservice architecture, one can choose a different technology stack for a service. E.g., some of the services use NodeJS, while other services use Python/Django and Postgres RDS. As you can see, one of the "benefits" of a microservice architecture is the ability to choose a right technology stack for a given service. All that matters is a common interface (e.g., HTTPS) which these services use to speak to one another. Such architecture allows cross-functional teams to develop, test, deploy, and update services independently. Most of the service can be deployed to production in less than 5 minutes. On the other hand, if we chose to build Graphene as a monolithic system, it may take at least 30 minutes to deploy even one line of code change. (Note that when we have too many flavors of technology stack to support, the operation cost also increases. But that's a topic for another article.)
In a monolithic system, there is normally a data interface between the business layer and the database (Fig. 1). The database becomes the bottleneck, because all data requests are handled by the same interface. As more and more features are added to the system, database schema becomes more complex. It is very hard to maintain and scale such system.
In microservice architecture, each service manages its own data. If data in service A is needed by service B, we need to bring the data from service A to service B for consumption. As you can see from Fig. 2, we have the Utility Service that listens for user data change events in external system. This is a typical publisher/subscriber model. In this model, any message published to a topic is immediately received by all of the subscribers to the topic. By using Pub/sub messaging we increase performance, reliability, and scalability.
To prevent user data from being out of sync, we need to maintain a FIFO event queue. When one service receives user data from the external system, it can rebuild the user data by replaying the events received. On top of the event replay, the service can also transform data, and map the data locally using its own data model. Such data transformation and local mapping makes it flexible when it comes to data exchange between services.
One thing we need to keep in mind is that, because user data spreads out in different service, there should be a common identifier to identify the shared object. For example, the user ID is used by all services in Graphene. This design ensures that we have a source of truth for the user data, and the data can be used by anyone, in any way, across the entire organization.
In our microservice architecture, Lambda and Step Function are widely used. They are all triggered by events in Graphene. By using Lambda, we do not have to worry about running and maintaining containers, which reduces our infrastructure cost, and make the system scalable as well.
Another pattern you may have noticed is the use of S3 bucket and SQS. In Fig. 2, the events are ingested from the service on the left. The events then go through multiple services in a chain. Graphene is thus an Event‐Driven Process Chain.
Building a modern, data-intensive microservice platform is hard. When decomposing the system into microservices, what goes into a service? If you have too many services, how do you manage and monitor these services? At KnowBe4, Graphene is the first system that requires our SRE to put a ton of work into finding new ways to avoid hitting hard AWS limits with OnDemand environment (See https://www.knowbe4.com/engineering/empowering-a-cloud-based-development-workflow-with-on-demand-environments-that-match-production).
Another challenge we faced is the authentication between different services. Currently if service A needs to send a HTTPS request to service B, both A and B have to know the secrets, and the secrets can only be shared by A and B. if there are a total of 10 services, to calculate the total number of secrets we need, we will use the formula C(n, 2) = n! / 2! * (n - 2)!, where n represents the total number of services. C(10,2) = 45. As n increase from 10 to 50, C(n,2) = 1225. You can see that it is impossible to manage all the secrets manually when we grow into 100 or even 1000 of services. In the future, we may need to investigate solutions like service mesh (https://cloud.google.com/architecture/service-meshes-in-microservices-architecture).
Do you want to join us to address these challenges? Have something to contribute? Passionate about purpose-driven, highly productive software development? Send us your resume! KnowBe4 Engineering is always looking for more talented engineers just like you! Check our open positions on our careers page - www.knowbe4.com/careers.


KnowBe4 Engineering heavily uses On-Demand environments for quick iterations on native cloud-based…

How KnowBe4 solved the "It Works on My Machine" problem with a new approach to provisioning test…