By: KnowBe4 HR
Published: 6 Jun 2022
Last Updated: 19 Jun 2026
A failing health check fired on November 3rd, 2020, alerting the Platform Engineering teams that the SCIM service was currently responding with a 503 Service Unavailable status to 100% of incoming requests. The service had just been released to all KnowBe4 customers the week prior, and many of our largest customers had already begun configuring the SCIM integration from within the console of their Identity Provider (IdP).
The HyperText Transfer Protocol (HTTP) 503 Service Unavailable server error response code indicates that the server is not ready to handle the request.
Common causes are a server that is down for maintenance or that is overloaded. This response should be used for temporary conditions and the Retry-After HTTP header should, if possible, contain the estimated time for the recovery of the service.
After a short period of time, AWS Fargate was able to leverage our auto-scaling policy and restore the service to full health without requiring any manual intervention from one of the members of our team. A few days later, another major outage spawned a longer, more thorough analysis of the SCIM service by the Core engineering team. The members of our incident response and engineering leadership teams were led through a Root Cause Analysis (RCA) of the incidents, from which we were able to identify a number of critical design flaws in the system. After researching the SCIM protocol, as it's defined by the official RFC documents, we learned that much of the protocol was not implemented in a way that would be compatible with many of the major IdPs. Consequently, the extent of the design flaws led us to deem rewriting the service to be the best course of action.
During a conversation with our stakeholders, we explained that the system would not be able to store and/or retrieve our enterprise customer's identity data due to its size, and the current system would need to be turned off immediately. Identity Management and Provisioning was the most commonly requested feature from our enterprise customers, and many future features of our products would be dependent upon a scalable, enterprise grade solution. Turning off the service was not really an option, so we needed to get creative. The SCIM service had fallen below our target SLO of 99.9% uptime, and all key indicators of service health illustrated that the problems would become magnified as new customers started using the service.
The System for Cross-Domain Identity Management (SCIM) protocol is the technical standard that defines the automated exchange of user identity information between domains and across IT systems. In our design, a customer's Identity Provider (IdP) provisions all the identities into a KnowBe4 platform service, which is then responsible for distributing this data to the various KnowBe4 products and services. If there is a disruption of service, any updates to a customer's identity data will not be synchronized with the state of the resources in the customer's IdP. This can result in missing or have incomplete identity data in one or more KnowBe4 products and services.
Over the past 90 days, the availability of the service has fallen below the target SLO of 99.9% availability in both the US (98.92%) and EU (99.76%) production environments.
The Core engineering team identified the root cause of the outage as resulting from the use of an inefficient relational data storage structure. Furthermore, it was determined in the RCA review meeting that a number of unclear specifications in the RFC may have been misinterpreted, and the open-source library that our engineers had tried to use was not compliant with many of the major IdP implementations of a SCIM provisioning client.
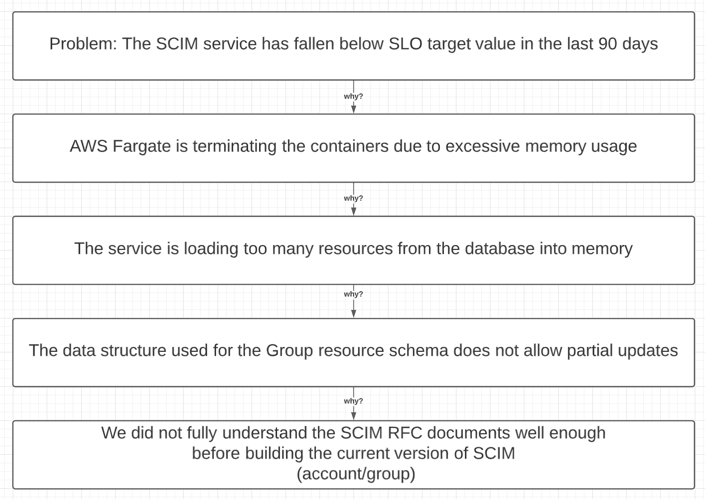
The first iteration of our SCIM service was unable to partially update the Users within a Group without pulling the entire Group—and its User Memberships—into memory from the database (DB) before applying the modifications. Consequently, these changes required an excessive amount of memory for even small to medium-sized Groups, rendering the service a non-viable solution for enterprise customers with Groups of hundreds of thousands of Users.
After the IdPs have finished provisioning the User and Group resources, future updates to the identity data are more frequently Group Membership changes rather than creating new resources. When a customer modifies their identity data from within their console, the IdP will push those updates to our SCIM service. Our logs revealed these updates could be too large to send in a single request, and that the IdP may split the updates for a single Group into multiple, concurrent requests. These requests were usually enough to exceed the provisioned memory allocation for the container, and the AWS Fargate service would respond by terminating our task(s).
On November 13th, 2020, the Core team created the Lock Patch Account Group feature flag, and implemented a blocking strategy within the SCIM API: multiple concurrent update requests to a Group resource would be rejected if found targeting a version of the resource already updated by an earlier request. By limiting the number of concurrent requests for a single Group, we successfully restricted the amount of memory usage of the service and significantly improved the reliability and overall health of the system.
The feature flag was used as an operational mechanism to apply blocking behavior to either individual accounts or a percentage of the total accounts, which allowed for testing of the short-term solution without affecting all customers utilizing the SCIM service at once. After the flag was enabled for all customers on December 14th, 2020, the production environments were no longer triggering alerts—the API containers were not liable to crash and completely stop serving requests. However, the service was still significantly far from healthy and had a number of technical problems that needed to be addressed immediately.
The first iteration of SCIM was written in Golang, heavily leveraging an open source library called go-scim. The service ran in AWS Fargate and stored data in a DocumentDB RDS cluster. Due to the cost model of statically provisioned infrastructure in AWS, the service was extremely cost inefficient because it had no correlation to the number of customers actually using the service. The majority of our spend went to large compute resources that were mostly idle, but needed to be available in order to handle sudden bursts of requests from an IdP. The rewrite of the service would need to be more financially viable, and would need to scale more dynamically than the provisioned infrastructure components used in the construction of the first solution. Because the SCIM codebase was so tightly coupled to the Mongo/DocumentDB data store implementation and an inactive open source project, we had no choice but to start from scratch.
The Core team was the newest team in Platform Engineering, and we had not yet established a primary programming language for our team before encountering our first major project. Many of our engineers were extremely skilled in a number of different languages, including Python, C#, Golang and Javascript; however, we did not all share the same primary language and split most evenly between Python and Golang. Some team members had been experimenting with Rust, and suggested we write a proof of concept (POC) to see if the low-level controls of Rust could be used as an advantage in potential future performance problems. Since performance was a major concern, we decided to try Rust (with Golang as a possible backup option) as it seemed to be a great fit from a technical perspective.
To summarize, our main reasons for choosing Rust were:
The obstacles we had to address when considering Rust for use on this project included:
The Core team consists of a large variety of technical backgrounds and philosophies. When we initially started working on the proof of concept, there was a strong difference of opinion in technologies, programming languages, and almost anything else technical. After working together to resolve the reliability and scalability issues that had plagued the initial SCIM service, our team members were excited about the possibility of learning Rust. We hoped that writing in Rust would make the project more engaging, as it provided a better set of tools that would make the problems more interesting to solve. Ultimately, the choice to write in the Rust programming language was and continues to be a uniting factor of the Core engineering team at KnowBe4!
The data structure used to persist the Group resource in the datastore was not designed in a way that would perform well with a large number of Memberships. There is not technically a max depth defined in the SCIM protocol, so the current data structure solution would likely crash the database engine if it attempted to process a Group large enough to exceed infrastructure limitations of the host.
When trying to use the same data structure to store the Group resources in DynamoDB, the DynamoDB service wisely rejected the document with an error message stating the content length of the document was too high. If the DocumentDB instance used in the V1 implementation of the SCIM protocol had thrown a similar error, it is incredibly likely that the data structure(s) would need revision rather than searching for an alternative datastore that would accept such a large, unmanageable data structure. Our new data module required storage that would process Membership modifications without loading the entire Group state into memory.
The initial alerts that sparked Platform Engineering’s investigation revealed the SCIM v1 design did not allow for the isolation of tenants while processing requests, one of the most critical concerns to address for a multi-tenant production service. Unfortunately, all customers using the SCIM service were processed by a long-running task in AWS Fargate. This lack of tenant isolation made the service susceptible to a noisy customer overloading it and causing it to be down for other customers.
The new design addressed the isolation of tenants by converting the infrastructure from an “Always On” traditional Fargate task-based service to an event-driven, serverless approach using Lambda functions behind an API Gateway. Ultimately, each request to the service would be processed by an isolated lambda invocation with its own memory allocation. This new infrastructure would isolate individual requests from one another, solving the problem of multiple tenants exceeding the memory allocation of the host.
After learning that the initial version of the service was never compatible with some requests made by the SCIM provisioning clients of the major IdPs, the Core team investigated a number of open-source and proprietary testing suites for the next version of the service. We were surprised to find a lack of accessible testing strategies, harnesses, or even examples of the SCIM protocols we had implemented. Most of the IdPs offered an outdated, or extremely simplified Postman collection, and did not have any performance or load related tests. In addition, most of the existing testing solutions for SCIM do not account for the complexity that exists in the Org Chart of enterprise customers. The Core team worked closely with the Software Engineers in Test (SET) team to build a robust testing harness that we could use to verify that the rewrite was completed successfully.
The rewrite of the SCIM service, code-named Charon, was released in October 2021, and is available for KnowBe4 customers today! 🎉
With SCIM integration, you can leverage user data from your identity provider to populate and maintain your users and groups within the KnowBe4 security awareness training and simulated phishing platform. This takes a huge burden out of user management by using this standardized method for importing and managing your users via a cloud service.
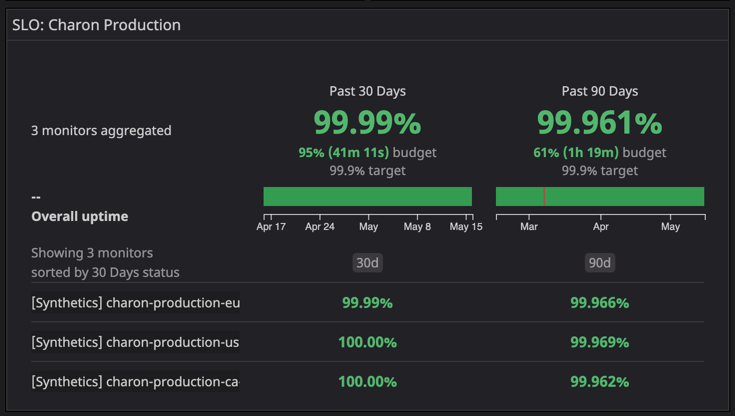
As of May 15th, 2021, the availability and reliability of the service have significantly improved due to the efforts and solutions included in the rewrite. Over the past 90 days, the SCIM service has featured 99.96% availability and the service has had over 99.99% availability in the past 30 days.
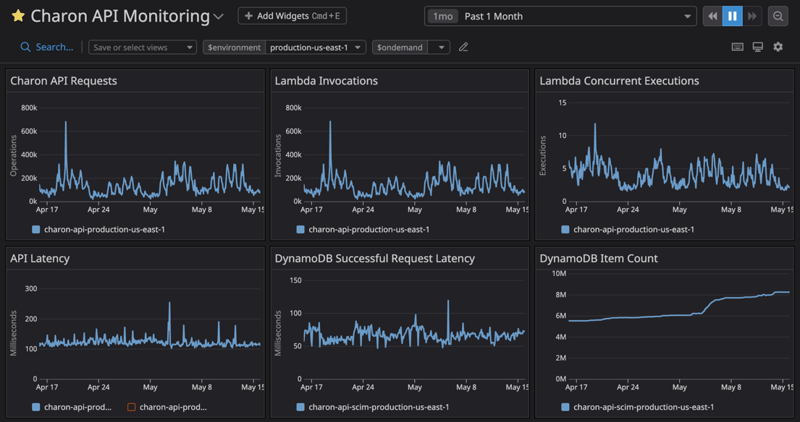
The API is able to scale almost instantly to account for the burst of requests it receives from our customer's IdPs and is able to access the stored identity data with an average latency of less than 150 milliseconds. Our largest environment has over 8 million items in the data store, accounting for more than 3.4 gigabytes of data across almost 2,000 KnowBe4 customers!
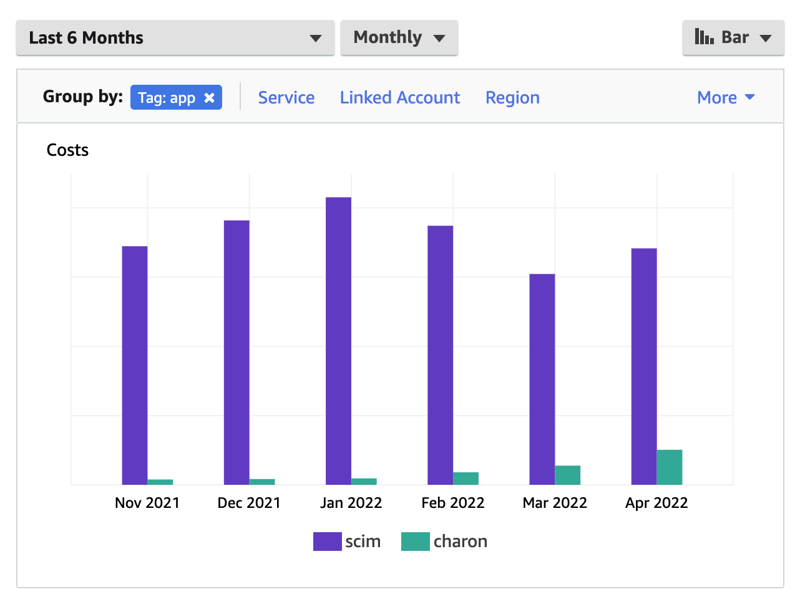
Over the past 6 months, the Charon version of the SCIM service has shown an average of 99.37% reduction in the operation cost of the service. In addition, the operational cost is now directly correlated to the number of customers we have on boarded to using the new system, rather than a static cost for provisioned infrastructure that cannot adjust in real time.
In addition, the original SCIM service was started on December 18th, 2019 and was released as a beta to mutual KnowBe4 and Azure AD customers on September 23rd, 2020. We were able to build the Charon service much more quickly, further reducing the overall cost of the project by minimizing the time it took to rebuild the service. The Charon system was started on November 23rd, 2020 and was released as a beta on May 21st, 2021.
Looking back on the SCIM project at KnowBe4, the most meaningful lesson we learned was that there is a subtle art to doing it right the first time. The combined effort of the original project and the rewrite ran for over 14 months, the majority of which was spent working on removing the original codebase from the final solution. Team members spent a significant amount of time, effort, and energy on various stages of testing, rework, and migrations that could have been avoided. The Charon project served as an opportunity to invest in our technologies, teams, and processes to better ensure we are doing things right the first time.
Using many of the patterns, strategies, and technologies that were introduced as part of the Charon project, our engineering teams have been able to accelerate the modernization of our platform. Many of the learnings around serverless technology, different programming languages, and highly available architectures featured in our internal Engineering Documentation System (EDS) were introduced to KnowBe4 engineering as a result of the Charon project. Fortunately, we were able to return value on the project in a number of ways that help to offset the overall cost of the mistake, while permanently resolving the technical issues the second time around!


KnowBe4 Engineering heavily uses On-Demand environments for quick iterations on native cloud-based…

How KnowBe4 solved the "It Works on My Machine" problem with a new approach to provisioning test…